
Toissaviikolla kävimme läpi mitä Power Platformin pyynnöt (requests) ovat, sekä mitä rajoituksia niihin liittyy. Nyt kun tiedämme etteivät ne ole ehtymätön luonnonvara, voimme miettiä miten niiden määrää voisi hillitä.
Power Apps
Power Apps on pyyntöjen osalta varsin turvallinen. Kunhan on varovainen toistuvien elementtien (galleria ja ForAll-funktio) sisällä tehtävien kyselyjen (LookUp, Filter, CountRows jne) kanssa.
Kuvan Power Appsissa on tilaukset (Demo_Orders) esittävä galleria. Kunkin tilauksen kohdalla näytetään montako tilausriviä siihen liittyy. Tekijä on oikaissut ja hakee jokaisen gallerian rivin kohdalla tilaukseen liittyvät rivit ja laskee niiden lukumäärän.
CountRows(Filter(Demo_OrderRows, OrderID = Text(ThisItem.ID)))
Tällainen ratkaisu on myrkkyä Power Appsin suorituskyvylle, koska se muodostaa huikean määrän pyyntöjä.
Power Apps Monitorista näemme mitä tapahtuu, kun gallerian tarvitsemat tiedot ladataan. 1380 Network-kategorian tapahtumaa!
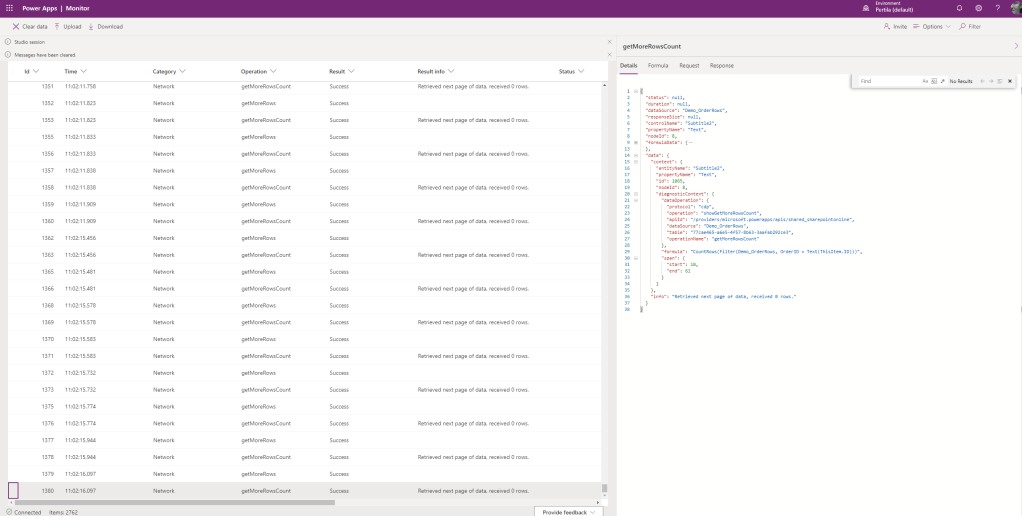
Miten tämä sitten pitäisi toteuttaa? Rivimäärä tulisi tallentaa tilaustietueeseen, jolloin gallerian sisällä ei tarvitse tehdä raskasta kyselyä. Mikäli tietovarastona on Dataverse, voi tarkoitukseen käyttää rollup-kenttää. Muissa tapauksissa tilauksen rivimäärä tulisi tallentaa tilaukselle aina sitä muokatessa.
Mikäli koko järjestelmässä on (aina) alle 2000 tilausriviä, voidaan ne hakea paikalliseen kokoelmaan ja gallerian sisällä viitata tähän kokoelmaan. Näin yhden tilauksen rivimäärän selvittäminen ei generoi pyyntöjä tietovarastoon.
Flow
Flow’ta käytettäessä on huomattavasti helpompaa tehdä epähuomiossa jotain, joka generoi järjettömän määrän pyyntöjä.
Flow’n käynnistys (Trigger)
Aivan ensimmäisenä tulee kiinnittää huomiota siihen, miten Flow käynnistyy. Mitä useammin se suoritetaan, sitä enemmän pyyntöjä syntyy. Mikäli Flow käynnistyy ajastetusti, on merkittävä ero käynnistyykö se perjantaisin, kerran päivässä, kerran tunnissa vai puolen tunnin välein.
Uutta ajastettua Flow’ta luotaessa on käynnistyksen oletusarvo kerran minuutissa. Mikä hirveä ajatus.

Mitä tällainen Flow pyyntömielessä kustantaisi? Se käynnistyy 60*24 = 1440 kertaa vuorokaudessa. Flow sisältää vähintään yhden toiminnon (Action), joten aivan minimissään tällainen Flow muodostaa vuorokaudessa 2880 pyyntöä.
Käyttäjän Office 365 -lisenssi sisältää 2000 pyyntöä vuorokaudessa.
Trigger Condition
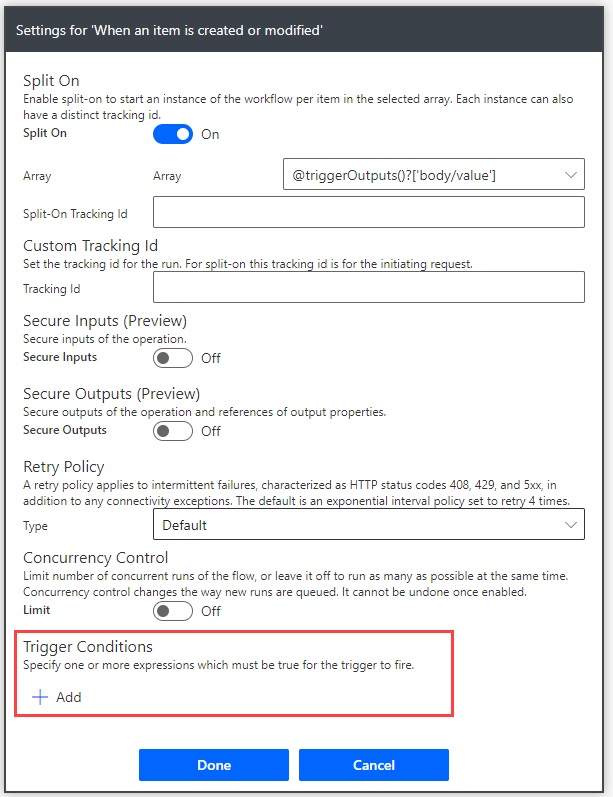
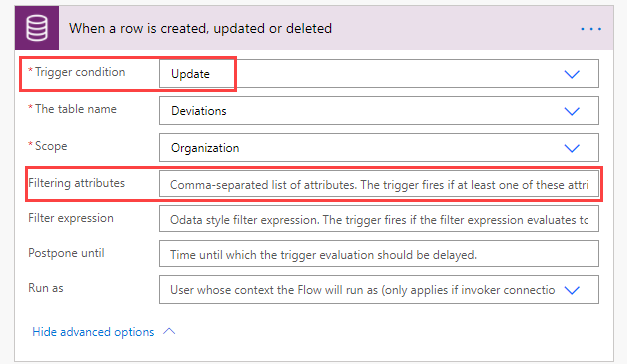
Mikäli Flow käynnistyy tietovarastossa tapahtuvasta muutoksesta (uusi rivi luodaan, joku muokkaa olemassa olevaa jne) on usein järkevää hyödyntää käynnistimen ehtoja (Trigger Conditions). Niiden avulla Flow määritellään käynnistymään esimerkiksi ainoastaan rivin tilatiedon tai vastuuhenkilön muuttuessa.
SharePoint-yhdistimessä tämä asetus löytyy käynnistimen asetuksista (settings).
Dataversen kanssa pääset hieman helpommalla.
Suodatus (Filter Query)
Suurin pyyntösyöppö Flow’ssa ovat silmukat. Haetaan vaikkapa kaikki tilausrivit ja tutkitaan jokaisen kohdalla erikseen kyseisen rivin tila.
Monesti päädytään kuvan kaltaiseen ratkaisuun.

Mikäli meillä on 5000 tilausriviä, joista ainoastaan yksi on uusi, aiheuttaa tämän flow’n suoritus 10003 pyyntöä.
Rivejä haettaessa tulee aina hakea vain ne kiinnostavat rivit. Esimerkissämme rivit, joiden tila on ”New”. Tämä onnistuu lisäämällä hakutoimintoon suodatuskyselyn (Filter Query).
Kuvan Flow muodostaa 4 pyyntöä äskeisen 10003 sijasta. Ja lopputulos on sama.

Turhat Compose-toiminnot
Joskus etsimiämme kenttiä ei löydy dynamic content-listalta. Syynä on useimmiten se, etteivät ne ole kohdekentän kanssa samaa tietotyyppiä.
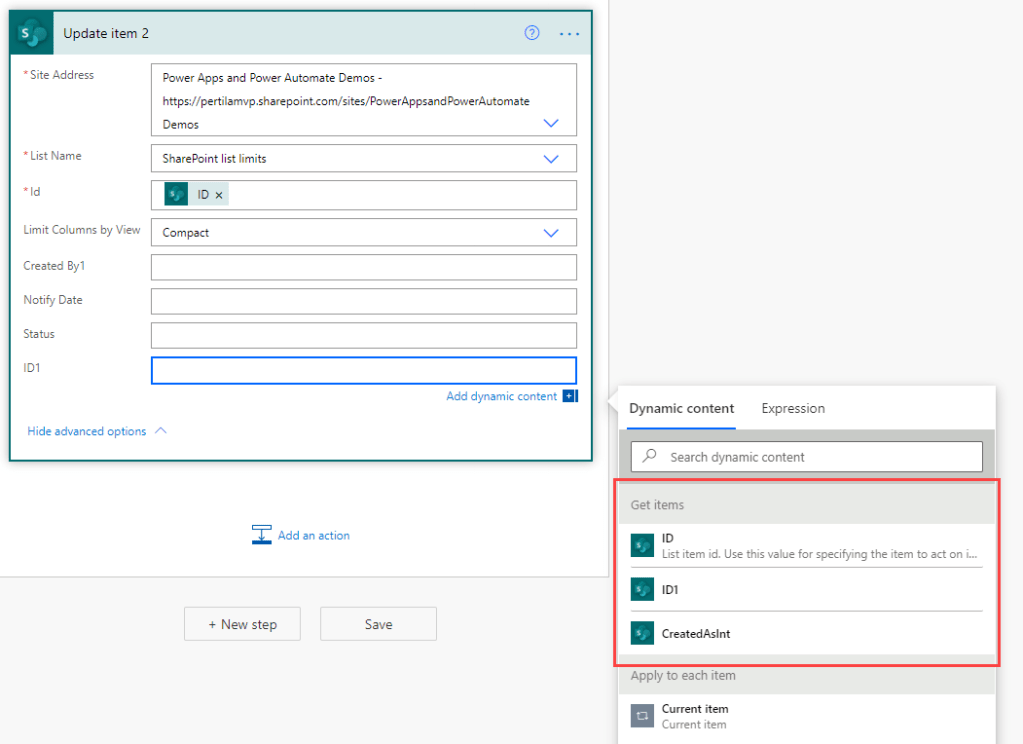
Helppo ratkaisu on poimia haluttu kenttä Compose-toimintoon ja käyttää sitä. Ei tarvitse miettiä tietotyyppejä.
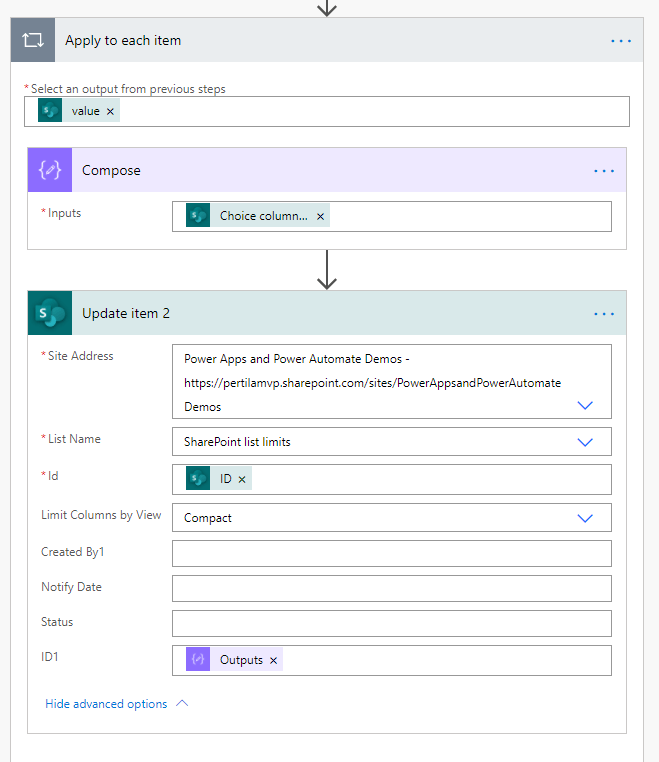
Joskus taas haluamme manipuloida tallennettavia tietoja. Tämä johtaa helposti seuraavanlaiseen ratkaisuun.
- Haetaan composeen luontipäivä
- Lisätään siihen x päivää (addDays)
- Muotoillaan syntynyt päivämäärä soveltuvaan muotoon (formaDateTime)
- Käytetään syntynyttä päivämäärää toiminnossa

Molemmissa on sama ongelma. Mikäli käymme läpi lukuisan määrän rivejä, generoi compose-toiminnot silmukan sisällä hirveän määrän turhia pyyntöjä.
Compose-toimintojen sisältämät kaavat voidaan tietenkin kirjoittaa yhdellä kertaa suoraan kenttään.

Esimerkissämme näin.
formatDateTime(addDays(items('Apply_to_each_item')?['Created'],20),'yyyy-MM-dd')Sisimpään silmukkaan voi viitata myös kevyemmin (item()).
formatDateTime(addDays(item()?['Created'], 20), 'yyyy-MM-dd')Kyselyn laajentaminen (Expand Query)
Kuvitellaan että pyöritämme Dataversessä poikkeamahavaintoja (Deviations). Haluamme kerran vuorokaudessa lähettää havainnon lisänneelle henkilölle (Created By) sähköposti-ilmoituksen kaikista poikkeamista, jotka ovat edelleen tilassa ”new”.
Suodatamme asianmukaisesti poikkeamat (cr59f_deviationstatus eq 441700000 tarkoittaa Status = ”New”), jonka jälkeen lähetämme sähköpostin. Mutta koska tietueen luoja on Lookup-kenttä, ei siitä löydy poikkeama-tietueelta kuin luojan tunniste (guid). Joudumme jokaisen rivin kohdalla hakemaan käyttäjä-taulusta (Users) kyseisen käyttäjän, jotta saamme tietoomme hänen sähköpostiosoitteensa. Tylsää.

Vastaavalla tavalla voimme joutua hakemaan muitakin tietoja.
Tämä on turha vaihe, sillä voimme laajentaa alkuperäistä kyselyä (Expand Query) siten, että tulosjoukko sisältää kenttiä myös relaatioiden takaa.
Esimerkiksi kaipaamamme tietueen luojan sähköpostiosoitteen.
createdby($select=internalemailaddress)Näin pääsemme eroon yhdestä kyselystä silmukan sisällä.

”Jokainen siivoaa jälkensä”
Otetaan loppuun vielä jotain hieman luovempaa.
Oletetaan että meillä on 1000 käyttäjän ratkaisu. Kukin käyttäjä luo päivittäin kymmenen uutta tietuetta. Päivittäin syntyy yhteensä 10 000 riviä. Haluamme arkistoida 30 päivää vanhemmat tietueet.
Helppoa. Ajastamme seuraavanlaisen Flow’n ajettavaksi kerran vuorokaudessa.

Mutta… 10000 tietueen poistaminen vie 20002 pyyntöä. Aika paljon. Flow’ta varten joutuu käytännössä ostamaan lisää pyyntökapasiteettia koska tuskin yhdelläkään käyttäjällä on näin paljoa pyyntöjä käytettävissään.
Lähestytäänkin arkistointia aivan toisesta suunnasta.
Laitetaan sovelluksen käyttäjät siivoamaan omat rivinsä. Eli hajautetaan siivoamiseen tarvittavat pyynnöt 1000 käyttäjän kesken. Helpointa tämä on sovelluksen käynnistyksen (App OnStart) yhteydessä.

Haetaan siis käyttäjän yli 30 päivää sitten luomat rivit ja poistetaan ne.
Set(varCurrentUser, User());
Set(varDate30DaysAgo, DateAdd(Now(),-30,Days));
ClearCollect(colMyOldItems, Filter('SharePoint list limits', 'Created By'.Email =
varCurrentUser.Email And Created < varDate30DaysAgo ));
Remove('SharePoint list limits',colMyOldItems);Mikäli käyttäjä käyttää sovellusta päivittäin, poistetaan aina max 10 riviä. Tästä syntyy 11 pyyntöä.

Toki jos käyttäjä on pitänyt sovelluksen käytössä taukoa, voi poistoa odottaa pahimmillaan 300 riviä.
Hieman työläämpi, mutta fiksumpi, ratkaisu onkin seuraava.
Tehdään Power Appsista käynnistettävä Flow, joka poistaa 30 päivää vanhemmat käynnistäjän luomat rivit.

Filter Query:ssä hyödynnetään triggerOutput-tiedoista löytyvää Flow’n käynnistäjän sähköpostiosoitetta.
Created lt '@{addDays(utcNow(), -30)}' and Author/EMail eq '@{triggerOutputs()?['Headers']['x-ms-user-email']}'Nyt Power Appsin käynnistyessä ajetaan tämä Flow. Vanhojen rivien poisto ei näy käyttäjälle mitenkään.

Ideaa voi jalostaa pidemmälle. Lisätään Flow’n alkuun 8 tunnin viive. Näin rivien poistaminen ei kuormita käytettävää tietovarastoa virka-aikaan, vaan poisto suoritetaan neljän jälkeen. Tarkka käynnistysaika riippuu siitä, milloin käyttäjä on sovelluksen käynnistänyt.

Rakentamamme poistoajo käynnistyy jokaisella sovelluksen käynnistyskerralla. Miten rajaisimme sen käynnistymään maksimissaan kerran vuorokaudessa?
Luodaan lista sovelluksen käyttäjistä (User Profile). Listalla ylläpidetään käyttäjittäin tietoa siitä, milloin poistoajo on viimeksi suoritettu (Old items deleted).
Päivitetään Flow’n alussa uusi aikaleima (utcNow()) käyttäjän profiliin.

Lopuksi päivitetään PowerAppsia siten, että käynnistyksen yhteydessä luetaan käyttäjäprofiilin tiedot ja käynnistetään Flow ainoastaan mikäli sitä ei ole tänään käynnistetty.

Jokainen voi sitten miettiä säästääkö tällä menetelmällä niin paljon pyyntöjä, että se on järkevä toteuttaa.
Tähän kiteytyy koko Power Platform pyyntörajoihin liittyvä tuska.
Milloin on järkevämpää kaivaa vain kuvetta ja ostaa lisää pyyntöjä vs optimoida ratkaisua? Optimointikin maksaa. Pahimmillaan se johtaa vaikeammin ymmärrettäviin (=ylläpidettäviin) ratkaisuihin ja se se vasta kallista onkin.
Toisaalta ylimääräisen kapasiteetin ja lisenssien hallinnointi maksaa sekin.
Jossain siellä välimaastossa on se turvallisin reitti. Optiomoidaan kaikki hölmöilyt pois, mutta siten että ratkaisut ovat vielä helposti luettavia. Ja loppu ratkaistaan lompakolla lisäkapasiteetin muodossa.
